26 Feb, 2014 von Philipp Hock 0
Few words about… The seek for a WhatsApp alternative
Since WhatsApp was sold for 19 billion dollar to Facebook, lots of blogs and news seek for alternatives. In this short comment, I will point out why we all need alternatives, why we all need more than one alternative, why this works and what features our new alternative must have.
Threema, Textsecure or Telegram are just a few new so called WhatsApp competitor nowadays. But before we go out and look for alternatives, we must understand what’s the problem with WhatsApp and Facebook. And before we consider that, we must understand why Zuckerberg payed 19 billion dollar for WhatsApp. I intentionally do not say that WhatsApp is worth that much money. It’s only that much worth for Facebook. The big deal shows us what really matters in the information age. Surprise, it’s information itself. Facebook itself is free, so where comes all the money? Facebook can afford buying WhatsApp, despite Facebook has not a single paying user. This tells us that information is very important and also very expensive. Important for advertising, marketing research or insurance companies. Or intelligence agencies. Information about us. Companies make billions of dollars by selling information they know about us!
The bad thing about this is, that we only understand why this can be a problem when it’s too late. When knowledge about us is used against us and we suddendly recognize it. Before that, we all agree using our personal information. And that’s bad.
So we note that information is important and we must take care of it.
For example by not giving a single company that much information. But there is more. It’s power. Facebook not only has our personal information, it has the power of more than one billion users. And there is almost no business competition.
So we note that using one centralized service supports monopolism and helps aggregating information.
So far, we’ve learned about the disadvantages of an information collecting centralized service. Now let’s have a look at why WhatsApp has so many users despite there are a lot of alternatives. When we read about apps having the potential to compete with WhatsApp, we always stumble upon the word usability. One of the main reason why WhatsApp is so successful, is because everyone can use it. You do not even have to register (explicitly). Registering is done almost instantly and implicitly
So we note that providing a real alternative to people, we must make the barrier of using our product very, very low by optimizing its usability. Features like group-chats or the ability to send multimedia files would increase the acceptance too. Platform support is also very important.
Let’s recap that. A chat system should protect our information. This can be done partially by using the right encryption. Partially, because meta data can be very difficult to encrypt. That means, data between two chatters can be strongly encrypted, but it’s hard to encrypt the information about who talks to each other (meta data). If we store the whole meta information collection at a single place (or company), we can hide what we are talking but not when, to who, where, how often and so on. For the latter, we must take a look at network topologies first. All communication in WhatsApp or Facebook end up at one server or server-cluster (see figure 1). A better alternative is using multiple independent servers. A decentralized system (see figure 2).

Figure 1: Centralized network topology.
Here, each server can be owned by another person or company. Communication is still possible between them because the Internet is designed that way. Think about email for example. Here we have the freedom of choice which provider we want to use. On top of that, we could use TOR (a network for the anonymization of connection data) to disguise even more of our meta data.
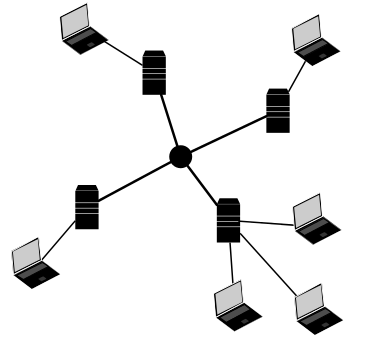
Figure 2: Decentralized network topology.
Another network topology we consider is the peer-to-peer architecture (see figure 3). Skype used to have this before Microsoft took it over. But Skype also fails somewhere else. At first, meta data is centralized. Second, it is owned by is a network for the anonymization of connection data one company (Microsoft). Third, it fails on it’s closed source nature. We cannot control or see what’s going on inside the system.
So we note that using an open source decentralized system is good. Also note that this is where most of the recently discussed alternatives fail completely.
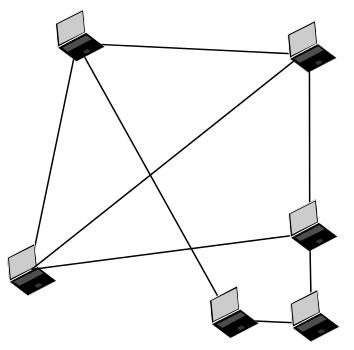
Figure 3: Peer-to-peer network topology.
Another problem with closed source is the denial of choice. For example the choice of crypto algorithms. In an open system, we can use any end-to-end encryption we want. And we want that choice because weak encryption is not considerable for us. We also want encryption that guarantees us deniability and perfect forward secrecy. Deniability means that nobody can proof that your conversation actually took place. Perfect forward secrecy means that if someone comes into possession of your password or encryption keys, your conversation cannot be decrypted afterwards. So we note that we need a system that allows us to use our own clients and our own encryption. Let’s summarize this. Our chat system must be decentralized, support any client and any end-to-end encryption,
be easy to use and support all available platforms. To make it short here, it already exists. It’s called XMPP and was developed in 1999.




